Metadatabreuken - laat ze jouw werk niet afbreken!
Een introductie tot metadatabreuken in een archief - wat ze zijn en hoe je ermee om kunt gaan
Gepubliceerd op: 24 januari 2024
Door Tim Manders (Beeld en Geluid) en Mari Wigham (Beeld en Geluid).
Het Beeld & Geluid archief bevat meer dan 2 miljoen items (programma’s, documenten en fysieke objecten) verspreid over meer dan 150 jaar. Dat representeert een enorme schat van kennis.

Figuur 1: Aantal archiefitems per jaar in het Beeld & Geluid collectie
Gebruikers die het archief raadplegen, stellen meestal een zoekvraag: ze willen materiaal kunnen vinden in het archief, zoals al het materiaal van André van Duin. Soms gaat het om een onderzoeksvraag, zoals “hoeveel materiaal is al gedigitaliseerd?” , “hoe vaak valt het woord ‘klimaat’ tijdens actualiteitenprogramma’s?” of “welke politici komen het vaakst aan het woord?”. In principe zou het archief in staat moeten zijn om zulke vragen te beantwoorden. Maar toch is het vaak lastiger dan verwacht, of zelfs onmogelijk - door metadatabreuken.
Wat zijn metadata?
Metadata zijn data die een archiefitem beschrijven, zoals de titel of een samenvatting. Zonder die beschrijvingen is het nagenoeg onmogelijk om iets te vinden in het archief. Metadata zijn de lens waardoor we het archief kunnen bekijken.
Metadata hebben veel verschillende bronnen. Ze kunnen vastgelegd worden door de makers van een programma, bijvoorbeeld in de vorm van de programmatitel en een samenvatting. Metadata kunnen later handmatig toegevoegd worden, bijvoorbeeld als een archivaris een programma bekijkt en beschrijft. Ze kunnen ook automatisch gegenereerd worden, zoals gebeurt bij de datum en tijd waarop een bestand is geüpload. Tenslotte kunnen metadata geëxtraheerd worden uit audiovisueel materiaal en bestaande metadata, bijvoorbeeld door personen te herkennen op beeld of in de beschrijving. Vaak worden AI-technieken (Artificial Intelligence = Kunstmatige Intelligentie) hiervoor gebruikt, waarbij software wordt getraind op data om metadata automatisch te kunnen genereren.
Wat zijn metadatabreuken?
Elke metadatabron heeft haar eigen karakteristieken. Een programmamaker legt dingen anders vast dan een archivaris en al helemaal anders dan een AI-algoritme. Verschillende types archiefitems vragen ook een andere aanpak - gezichtsherkenning is waardevol op televisiemateriaal maar waardeloos op radio. Verschillen in hoe metadata zijn vastgelegd noemen we metadatabreuken. Deze breuken zijn als krassen op onze metadatalens. Ze veroorzaken blinde vlekken en vertekenen onze blik op het archief.
Wat veroorzaakt metadatabreuken?
Metadatabreuken ontstaan met name door veranderende selectiepraktijken bij archieven en door gebruik van verschillende manieren om metadata vast te leggen.
Selectie van materiaal
Het meest fundamentele verschil in metadata is of een item wel of niet in het archief aanwezig is. Een archief bewaart niet alles. Er worden keuzes gemaakt welk materiaal wel en niet wordt bewaard. Met andere woorden: er wordt geselecteerd. Beeld & Geluid bijvoorbeeld bewaart televisieprogramma’s alleen als ze zijn gemaakt in Nederland. Buitenlandse programma’s belanden niet in het archief. Een item dat niet in het archief aanwezig is, heeft ook geen metadata. Dit lijkt een open deur, maar voor gebruikers die niet weten hoe de selectie is gedaan, kan het enorm verwarrend en frustrerend zijn wanneer ze niet vinden wat ze zoeken.
Verschillende manieren van metadatering
Zoals al besproken, kunnen metadata op verschillende manieren worden vastgelegd. Automatische technologie zoals AI heeft de potentie om veel meer materiaal te beschrijven dan een archivist ooit handmatig zou kunnen doen maar levert andere resultaten. Bijvoorbeeld een AI algoritme die term-extractie gebruikt kan een programma taggen met de term ‘klimaat’ omdat dat woord vaak wordt genoemd, terwijl een archivist die trefwoorden toekent aan een programma het kan taggen met de term ‘klimaat’ omdat het onderwerp daarin wordt besproken, ook al wordt het woord zelf nooit genoemd.
Welke metadata worden vastgelegd en hoe dat gebeurt, hangt samen met het type materiaal en de beschikbare middelen. Echter, zelfs binnen een bepaalde manier van metadatering kunnen er veel keuzes gemaakt worden. Het heeft overduidelijk geen zin om automatische spraakherkenning toe te passen op een decorontwerp. Toepassing van Nederlandse spraakherkenning op programma’s met veel muziek of buitenlandse talen is ook minder zinvol. Waar middelen beperkt zijn, kunnen bepaalde typen materiaal voorrang krijgen. Bij Beeld & Geluid is het bijvoorbeeld mogelijk om gezichten te herkennen in beeldmateriaal. Echter, deze technologie is best duur. Daarom wordt deze technologie alleen toegepast op bepaalde genres, zoals nieuws, en alleen voor de mensen die vaak voorkomen in hedendaagse media. Het gebruik van hulpmiddelen, zoals een thesaurus (een beheerde lijst van begrippen), heeft ook gevolgen voor de kwaliteit van metadata: als personen consistent worden vastgelegd met een thesaurusterm, hinderen verschillen in schrijfwijze van namen het zoeken niet langer, echter door beperkte middelen wordt niet iedereen in de thesaurus vastgelegd.
Figuur 2 laat zien hoe de beschikbaarheid van onderwerp-informatie voor een archief-item sterk afhangt van de categorie van de item.
Figuur 2: Percentage archiefitems met onderwerp-informatie voor een aantal geselecteerde categorieën
Het beleid van een archief - welke manieren van metadatering zijn gekozen en ingezet - maakt dus veel uit voor de metadata die worden gecreëerd. Beeld & Geluid is ontstaan uit de fusie van omroep-, film- en wetenschappelijke archieven. Elk instituut bracht zijn eigen metadata mee, vastgelegd vanuit een eigen beleid. Elke bron van metadata bevatte haar eigen metadatabreuken en de verschillen tussen de metadata van verschillende instituten vormen ook metadatabreuken.
Veranderingen over tijd heen
Beleid rondom metadatering verandert ook over de tijd heen, zoals wanneer er nieuwe vormen van archiefitems ontstaan (denk aan digitale en sociale media), selectiebeleid wordt aangepast, nieuwe manieren van metadatering worden ingevoerd of richtlijnen worden geüpdatet. Bij elke verandering - ook als de verandering tot betere metadata leidt - ontstaat er een nieuwe metadatabreuk.
In onderstaande grafiek is het duidelijk dat nieuwer Beeld & Geluid-materiaal veel minder onderwerp-informatie heeft dan ouder. Dit komt door de overstap van handmatige metadata-annotatie door archivarissen naar annotatie door makers en door automatische methodes.
Figuur 3: Percentage archiefitems met onderwerp-informatie voor en na 2014
Beeld & Geluid metadatabreuken
Het archief van Beeld & Geluid heeft een rijke geschiedenis en daardoor ook een grote hoeveelheid metadatabreuken. Om inzicht te geven in de belangrijkste metadatabreuken, hebben we deze in figuur 4 op een tijdslijn beschreven. We behandelen de twee oorzaken van metadatabreuken (selectie en metadatering) in de context van het Beeld & Geluid archief. We noemen ook ‘opschuddingen’: momenten waarop er een grote verandering is die verregaande gevolgen heeft voor selectie/en of metadatering.
De tijdslijn brengt alle oorzaken samen. Beweeg met je muis over een bolletje om er meer over te lezen
Figuur 4: Een tijdslijn van metadatabreuken bij Beeld & Geluid
NB: De tijdslijn vertelt niet het hele verhaal, omdat op ieder moment in de tijd er ook verschillen zijn in hoe verschillende types materiaal worden behandeld. In het tijdperk van handmatige annotatie gaven archivarissen bijvoorbeeld prioriteit aan bepaalde genres, waardoor sommige items een gedetailleerde beschrijving kregen en andere een meer summiere.
In de volgende secties bespreken we selectie, metadatering en opschuddingen in meer detail.
Selectie
De selectiemomenten (blauwe bolletjes) representeren momenten van belangrijke veranderingen in het selectiebeleid van Beeld & Geluid, met metadatabreuken als gevolg. In het begin archiveert Beeld & Geluid alleen materiaal dat aan het instituut wordt aangeboden door de producenten. Als de omroepen in 1970 magneetbanden in gebruik nemen om materiaal te archiveren neemt de hoeveelheid materiaal toe. Het regelmatig archiveren van radio begint in 1977, wordt uitgebreid vanaf 1997 en sinds 2006 worden alle publieke radiozenders volledig gearchiveerd. Het regelmatig archiveren van TV begint in 1990 en sinds 2006 worden alle Nederlandse producties op TV gearchiveerd. Zowel Nederlandse als niet-Nederlandse muziek wordt gearchiveerd voor hergebruik. Bijzondere moeite wordt gedaan om Nederlandse producties te bewaren. Vanaf 2014 neemt Muziekweb het archiveren van muziek over. In 2017 fuseert het Nederlands Persmuseum met Beeld & Geluid, en in 2022 fuseert Muziekweb met Beeld & Geluid. Als de metadata van het Persmuseum en Muziekweb wordt geïntegreerd in de systemen van Beeld & Geluid, ontstaan er opnieuw metadatabreuken.
Metadatering
De metadatamomenten (gele bolletjes) representeren momenten van belangrijke veranderingen in hoe metadata worden gegenereerd bij Beeld & Geluid. In 1997 beginnen alle archivarissen bij Beeld & Geluid met één catalogussysteem te werken voor film, TV en radio. Consistentie wordt verder bevorderd door het invoeren van de GTAA thesaurus in 2001, zodat documentalisten termen uit de thesaurus gebruiken in plaats van zelf een term in te typen, eerst voor genres en onderwerpen en vanaf 2004 ook voor personen, organisaties en locaties.
Als vanaf 2006 door veranderingen in selectiebeleid de hoeveelheid materiaal toeneemt, verschuift het beleid van het selecteren en uitgebreid beschrijven van weinig materiaal naar het selecteren en in verschillende maten beschrijven van meer materiaal. De beperkte annotatiekracht wordt zo gericht ingezet voor materiaal waaraan een hogere prioriteit wordt gegeven. TV, waarvan minder programma’s worden gearchiveerd dan radio, wordt typisch in meer detail beschreven dan radio.
Figuur 5 toont twee voorbeelden van verschillende annotatieniveaus bij handmatige annotatie. Het eerste voorbeeld is een aflevering van het politiekprogramma Buitenhof uit 2009. Dit programma werd uitgebreid geannoteerd met o.a. een samenvatting van het programma en informatie over personen, locaties en onderwerpen. Er is ook technische informatie, zoals het aspect ratio en de programmalengte. Het programma is zelfs uitgesplitst in segmenten die individueel worden beschreven. Het tweede voorbeeld komt vanuit hetzelfde jaar, maar is een programma, Boeken, dat vanwege zijn genre op een lager niveau werd geannoteerd. Het bevat wel technische informatie, maar de inhoudelijke informatie is beperkt tot één persoonsnaam en een beschrijving van een externe bron.
 |
| Een uitgebreid geannoteerd programma, Buitenhof. |
 |
| Het programma is ook in segmenten onderverdeeld, die in detail zijn geannoteerd. |
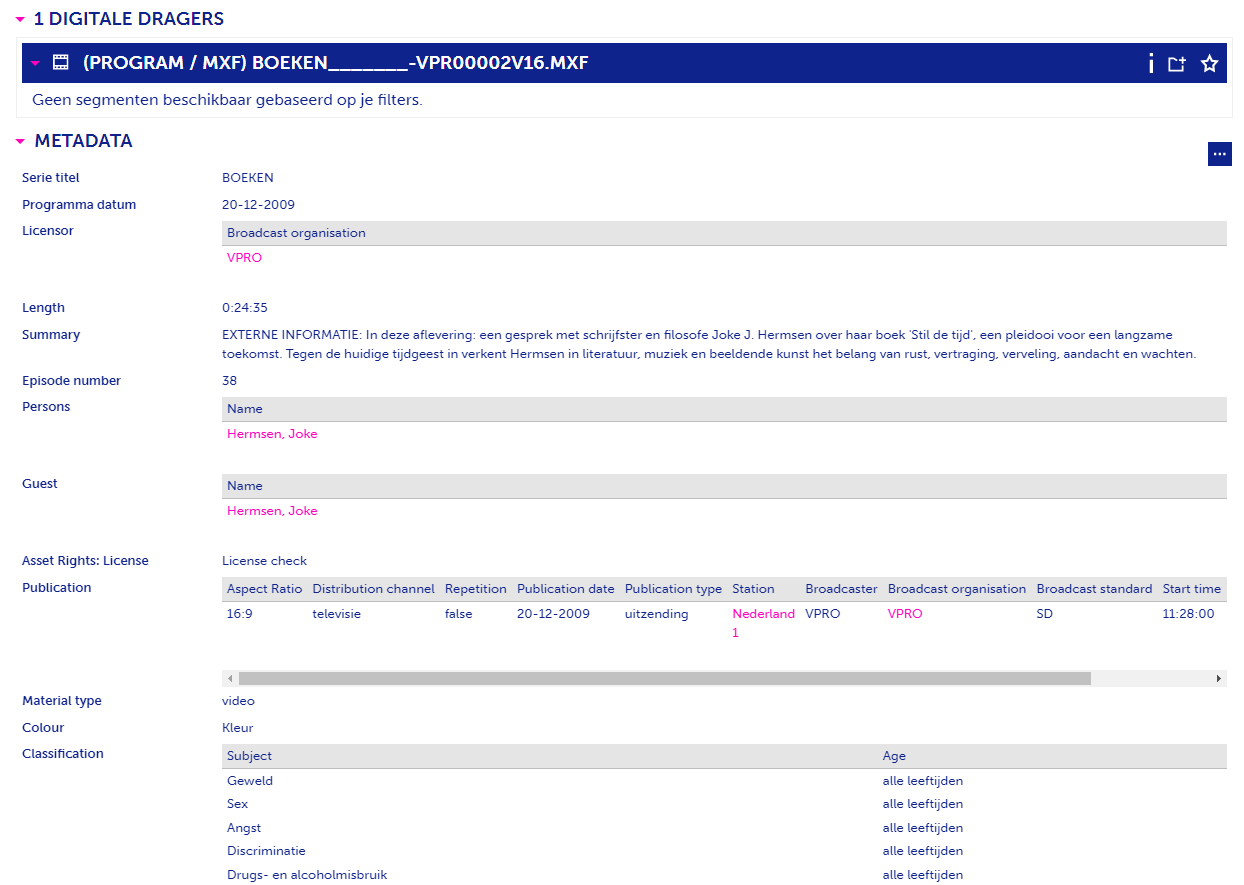 |
| Een summier beschreven programma, Boeken. |
Figuur 5: Example of varying annotation levels
In 2012 start Beeld & Geluid het Media Management programma. Dit is een serie projecten gericht op het verkrijgen van betere metadata vanuit de bron en automatisering van annotatie. Het luidt een tijdperk in van grote veranderingen in metadata, en vanaf 2015 wordt handmatige annotatie door archivarissen sterk afgebouwd, en de voorkeur gegeven aan het ophalen van metadata bij de programmamakers zelf en door sprekerherkenning (vanaf 2015) en gezichtsherkenning (vanaf 2019).
Opschuddingen
Op sommige punten in de geschiedenis van Beeld & Geluid is er sprake van een ‘opschudding’, een verandering die verregaande gevolgen heeft voor de selectie en metadata (paarse bolletjes; de verticale stippellijnen illustreren de gevolgen voor ‘selectie’ en ‘metadatering’). De invoering van een nieuw metadatabeheersysteem1 (een softwaresysteem waarmee metadata worden ingevoerd, bewaard en doorzocht) in 1997, 2006 en 2018 zorgt telkens voor een opschudding. Het grootschalige digitaliseringsproject ‘Beelden voor de Toekomst’ zorgt ook voor een aardverschuiving in de metadata door een grote instroom van gedigitaliseerd materiaal.
Impact van metadatabreuken
Metadata zijn de lens waardoor we naar het archief kijken. Metadatabreuken zijn zoals krassen op deze lens. Ze verstoren ons zicht op het archief. Dat heeft gevolgen voor het zoeken en onderzoeken.
Impact op zoeken - en vinden
Selectie heeft de grootste impact op het kunnen vinden wat je zoekt. Uiteraard kunnen gebruikers niet vinden wat niet is geselecteerd om te bewaren in het archief. Echter, gebruikers weten dat niet als ze niet bekend zijn met het selectiebeleid. Ze begrijpen dan niet waarom ze iets niet vinden. Metadatabreuken beïnvloeden ook de vindbaarheid van items. Een item met een gedetailleerde beschrijving, een spraaktranscript en een lijst van personen, organisaties en locaties is veel makkelijker te vinden dan een item met alleen summiere informatie.
Soms is de informatie er wel maar maken veranderingen in metadatering het vinden moeilijker. Kijk naar dit voorbeeld van zoeken op “Dolf Jansen” in ons archief (figuur 6 hieronder). De effecten van archiefbeleid zijn duidelijk te zien met betrekking tot de vindbaarheid van items. Eerst komt de naam alleen voor in vrije tekstbeschrijving, daarna als thesauruspersoon en pas recent in stem- en gezichtsherkenning. Alleen als gebruikers in al deze metadatavelden zoeken, krijgen ze zo veel mogelijk zoekresultaten. Als ze dat niet weten, vinden ze veel minder materiaal dan er is.
Figuur 6: Het aantal zoekresultaten per jaar voor Dolf Jansen in verschillende metadatavelden
Impact op onderzoeken
De impact op onderzoeken is nog groter. Om conclusies te trekken, heb je het liefst een compleet beeld. Waar dat niet mogelijk is, is het essentieel om de beperkingen te kennen, om daar rekening mee te kunnen houden. Een onderzoek naar welke politici spreken in de media, bijvoorbeeld, zal alleen politici vinden waarvoor er een sprekersmodel is. De onderzoeker moet beslissen of deze beperking acceptabel is voor hun onderzoek of niet.
Analyse van ontwikkelingen over de tijd heen wordt erg bemoeilijkt door veranderingen in metadata. Bijvoorbeeld, informatie over onderwerpen werd vroeger door archivarissen vastgelegd, nu nauwelijks meer. Recent materiaal heeft vaak wel ondertitels of een transcript waarbinnen er gezocht kan worden op een term. Echter, zoals eerder besproken, is er een aanzienlijk verschil tussen het voorkomen van het woord ‘klimaat’ in een transcript en de keuze van een archivaris om een programma te taggen met de thesaurusterm ‘klimaat’. Als een onderzoeker de ontwikkeling van het klimaatdebat wil analyseren a.d.h.v. in hoeveel programma’s het onderwerp is besproken, dan moet ze rekening houden met deze verschillen. Bijvoorbeeld dat relevante programma’s misschien niet zijn getagd, als het programma niet werd beschreven of de archivaris van toen niet vond dat het onderwerp significant was. En dat ze misschien onterecht programma’s meetellen adhv transcripten, als het woord klimaat genoemd werd maar het programma ging er niet over (‘Volgende week bespreken we het klimaat…’, ‘We hebben het hier niet over het klimaat’) of als het woord in een andere context werd gebruikt (‘In dit economische klimaat…’). Onderzoekers die zich niet bewust zijn van deze factoren, krijgen gewoon resultaten van hun analyses. Maar deze resultaten kunnen vertekend zijn door de metadatabreuken, waardoor de onderzoeker verkeerde conclusies kan trekken. Bijvoorbeeld de conclusie dat in het verleden het klimaat niet besproken werd in entertainmentprogramma’s, terwijl die programma’s simpelweg een lagere prioriteit hadden en dus vaak niet zijn beschreven.
Naar aanleiding van 70 jaar televisie in 2021 wilden we kijk- en luistercijfers analyseren om de meest populaire programma’s te identificeren. Dit was echter onmogelijk. Allereerst bleken kijk- en luistercijfers niet voor de hele periode beschikbaar. Daarnaast waren er binnen de periode waarvoor ze wel beschikbaar waren grote verschillen in de structurering van de data en was de manier waarop kijken en luisteren werd geregistreerd enorm veranderd (zie figuur 7).
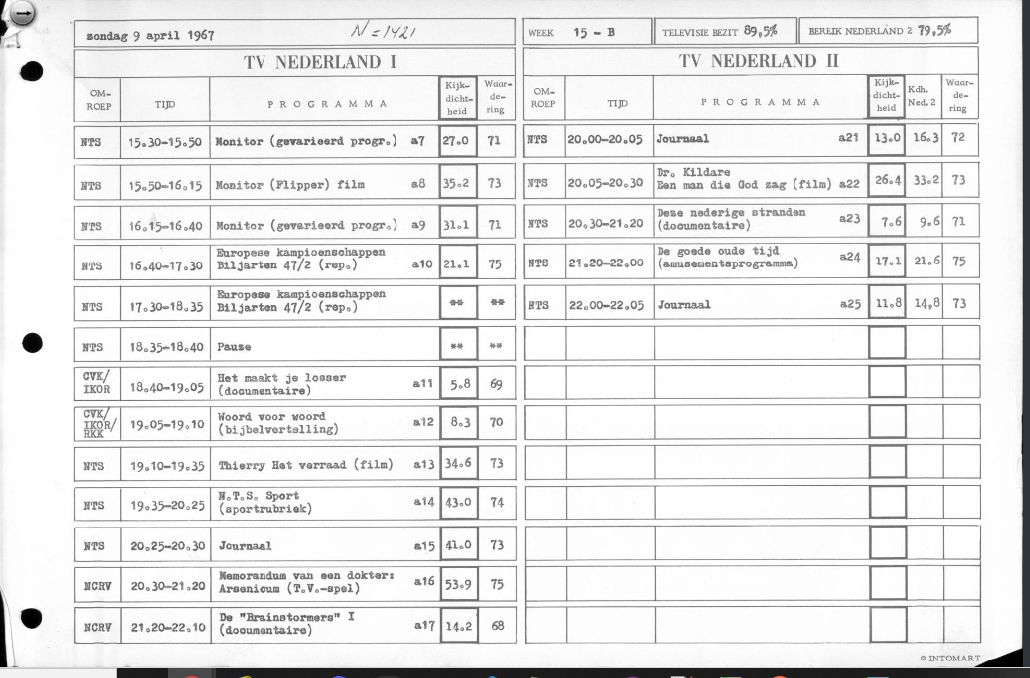 |
| 1967 |
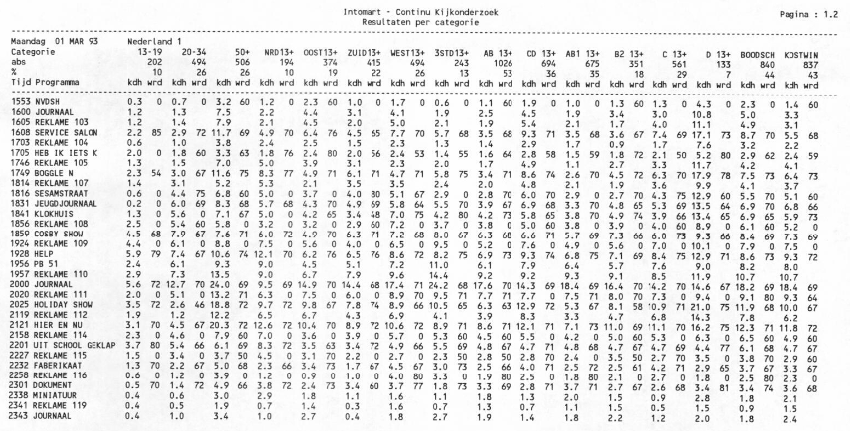 |
| 1993 |
Figuur 7: Voorbeelden van verschillend gestructureerde kijk- en luistercijfers.
Hoe gaat Beeld & Geluid om met metadatabreuken?
Dit verhaal is onderdeel van een initiatief van Beeld & Geluid om metadatabreuken in kaart te brengen en goed te beschrijven. Zo kunnen archiefgebruikers goed geïnformeerd aan de slag met het archief. Bewustzijn van metadatabreuken geeft de gelegenheid om er verantwoord mee om te gaan, bijvoorbeeld door de juiste keuze te maken bij het doorzoeken van metadatavelden of het bedenken van zoektermen.
Hoe ga jij om met metadatabreuken?
Wil je beter kunnen zoeken in het archief? Wil je goed begrijpen wat je wel en niet vindt, waardoor dat komt, en hoe je daar rekening mee kunt houden? Dan zijn de volgende stappen belangrijk:
- Lees documentatie over metadatabreuken (dit verhaal is een goed begin);
- Denk goed na over je zoek- en onderzoeksvraag. Welke metadata gebruik je? Over welke tijdsperiode? Welke metadatabreuken spelen voor jou dan een rol?;
- Toon je bewust van de metadatabreuken in het onderdeel van het archief dat jij onderzoekt;
- Kijk of je de metadatabreuken kunt omzeilen - bijvoorbeeld door een ander metadataveld te kiezen, een meer homogene subcollectie te doorzoeken, je vraag aan te passen of je analyseresultaten te corrigeren voor vertekening;
- Gebruik de tools die de Media Suite (een onderzoeksomgeving voor o.a. het Beeld & Geluid archief) aanbiedt.
Media Suite tools
De Media Suite geeft toegang tot de metadata van een aantal belangrijke mediacollecties, waaronder diverse collecties van Beeld & Geluid. Daarnaast biedt de Media Suite ook tools om met deze metadata te werken.
De Inspect tool is voor iedereen beschikbaar. Deze toont statistieken waarmee je metadatabreuken goed kunt opsporen, door te kijken naar de volledigheid van metadatavelden, ook over de tijd heen.
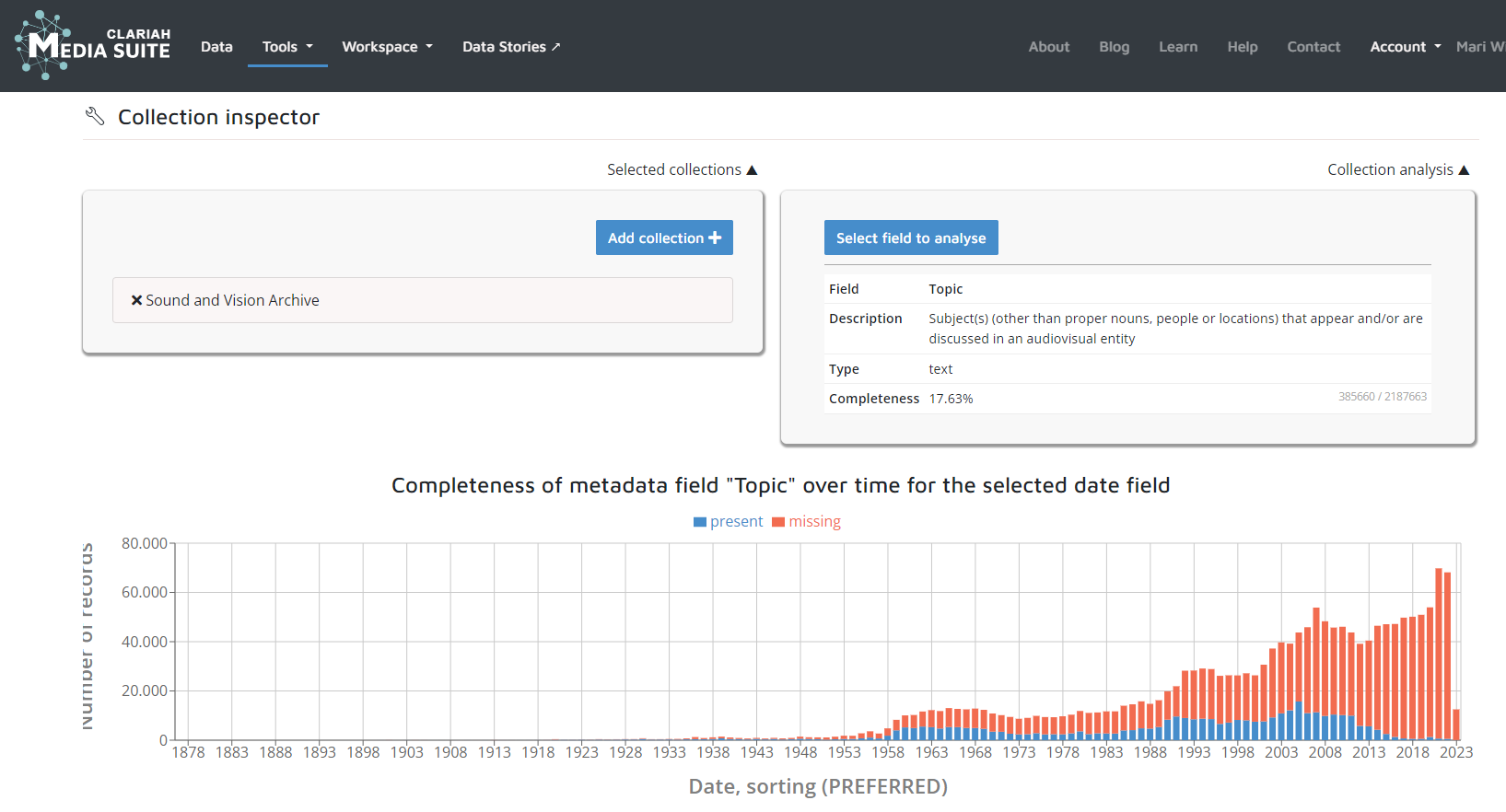
Figuur 8: Screenshot van de Media Suite Inspect Tool - deze laat duidelijk zien hoe de hoeveelheid items met een onderwerp is veranderd over de tijd heen.
Figuur 8 hierboven is een screenshot van de Media Suite Inspect Tool en laat duidelijk zien hoe de hoeveelheid items waarbij het metadataveld “onderwerp” is ingevuld steeds verder afneemt.
De Compare tool is beschikbaar voor academische onderzoekers en Beeld & Geluid medewerkers. Deze maakt het mogelijk om de resultaten van verschillende zoekvragen te vergelijken. Daarbij geeft deze tool je de mogelijkheid te compenseren voor metadatabreuken. Zo analyseerden onderzoekers in het MediaOorlog-project oorlogskranten in de Media Suite. De kranten werden toegekend aan de categorieën ‘Genazificeerd’ en ‘Anti-nazi’. Er waren veel meer kranten in de ‘Genazificeerd’-categorie dan in de categorie ‘Anti-nazi’. Als we zoeken op bijvoorbeeld ‘Stalingrad’, dan zijn de aantallen krantenartikels met dat woord uiteraard hoger in de ‘Genazificeerd’-categorie dan in ‘Anti-nazi’. Door naar percentages te kijken in plaats van naar absolute aantallen, kunnen we compenseren en zien we een heel ander patroon (zie figuren 9 en 10 hieronder).
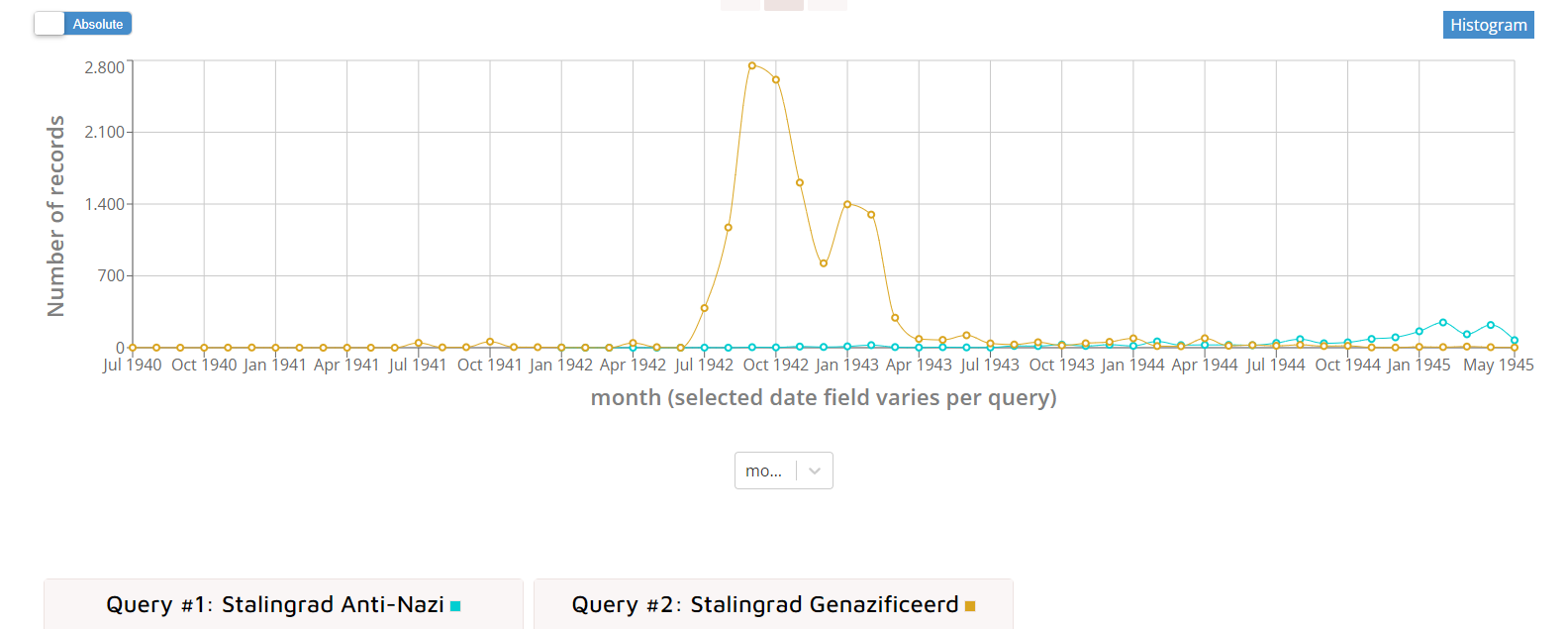
Figuur 9: Screenshot van de Media Suite Compare Tool - de absolute aantallen krantenartikels met de term 'Stalingrad' in genazificeerde en anti-nazi kranten.
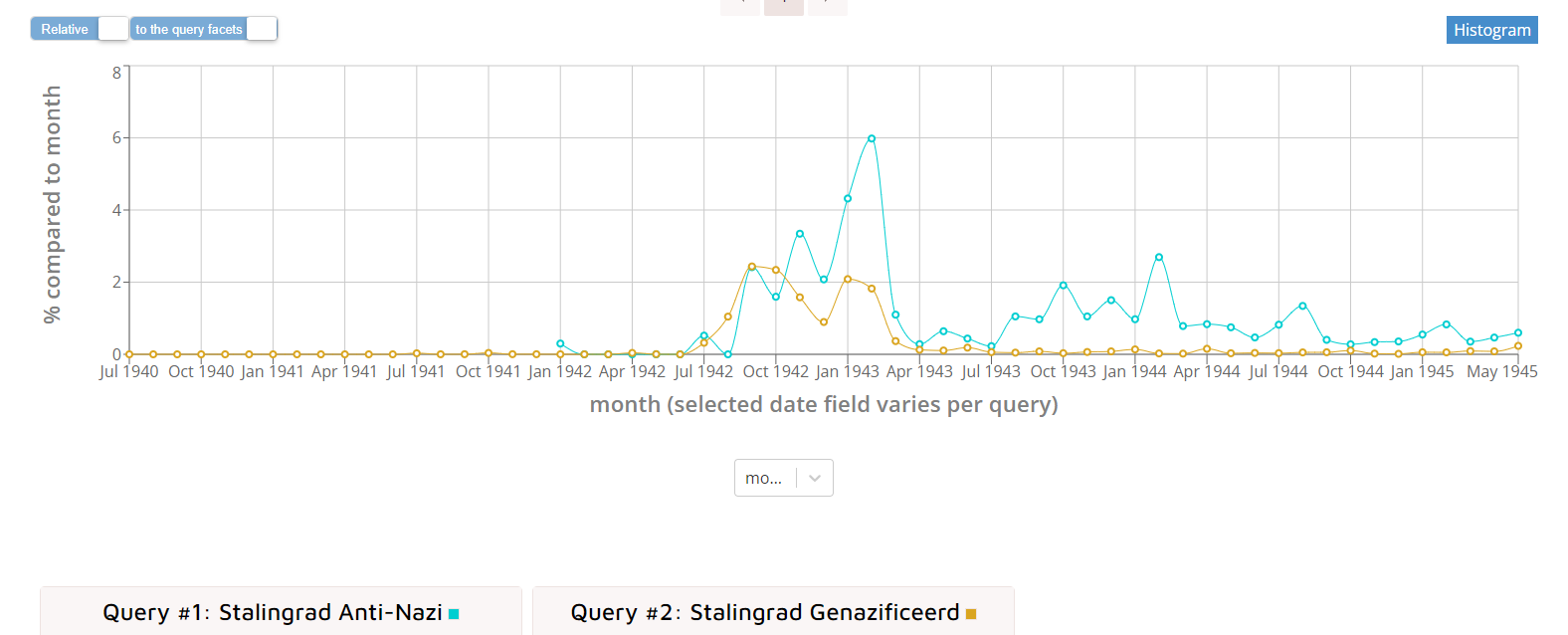
Figuur 10: Screenshot van de Media Suite Compare Tool - de relatieve aantallen krantenartikels met de term 'Stalingrad' in genazificeerde en anti-nazi kranten.
Conclusie
Metadatabreuken zijn inherent aan een rijke en historische archiefcollectie die over tijd steeds groeit en zich ontwikkelt. Ideeën over archiveren veranderen, er komen nieuwe technologische mogelijkheden en ook de wensen van de samenleving veranderen. Dat leidt tot veranderingen in de selectie en in manieren van metadatering waardoor metadatabreuken ontstaan. Sommige keuzes hebben verregaande effecten (opschuddingen).
Om hiermee als archiefgebruiker goed om te gaan, is bewustzijn een eerste stap. Bij Beeld & Geluid hebben we in de Media Suite specifieke informatie en tools die kunnen helpen metadatabreuken op te sporen, te begrijpen en te compenseren. Zo kun je alsnog het beste halen uit de schat aan informatie in het archief.
Dankwoord
Met dank aan Vincent Huis in 't Veld, Cor van Veen, Willemien Sanders en Yvonne Peters voor hun waardevolle kennis en feedback.
De Media Suite is ontwikkeld in het CLARIAH-project.
Footnotes
- We hebben in dit verhaal de focus gelegd op de metadatabeheersystemen van TV en Radio. We zullen in de toekomst meer informatie toevoegen over andere systemen. ↩